Cloudflare Down Highlights: Global Outage Disrupts Major Web Services
News Updated on : November 19, 2025Millions of websites were affected by a sudden technical failure at Cloudflare, a vital internet infrastructure provider. A major Cloudflare outage has disrupted several leading platforms, causing widespread accessibility issues across websites and mobile apps.
The outage was reported at 11.48 UTC (all times in this blog are UTC), the company said, “A fix has been implemented, and we were able to resolve the impact of traffic flowing through our network approximately.”
Sharing an update on the recovery of our services. We were able to resolve the impact to traffic flowing through our network at approximately 14:30 UTC, which was our first priority, but the incident required some additional work to fully restore our control plane (our dashboard… https://t.co/SQR2KdsrX0
— Dane Knecht 🦭 (@dok2001) November 18, 2025
Users reported being unable to load services like X, ChatGPT, Spotify, Canva, Perplexity, and many others. By evening, reports on Downdetector had surged into the thousands, highlighting the scale of the incident. The disruption appears to stem from Cloudflare’s infrastructure, which powers traffic management, security, and performance optimization for a vast network of online platforms.
Which services were affected by the outage?
A wide range of popular platforms experienced slowdowns, loading failures, or complete downtime due to the Cloudflare outage. The official Cloudflare blog listed the services affected by the outage.
| Service / Product | Impact Description |
| Core CDN and Security Services | Spike in HTTP 5xx status codes; users saw standard Cloudflare error pages. |
| Turnstile | The service failed to load entirely, preventing users from completing verification steps. |
| Workers KV | High levels of 5xx errors due to failures at the front-end gateway caused by proxy issues. |
| Dashboard | Mostly functional, but many users could not log in because Turnstile wasn’t working on the login page. |
| Email Security | Temporary loss of an IP reputation source affected spam-detection accuracy; some Auto Move actions failed but were later reviewed and corrected. |
| Access | Widespread authentication failures for most users until rollback at 13:05. Existing sessions remained active. Login errors prevented users from reaching target applications. Configuration updates during this time failed or propagated slowly. |
| CDN Response Latency | Significant latency increases as debugging systems consume large amounts of CPU while improving error detection with diagnostic data. |
Furthermore, several high-traffic websites and applications that rely on Cloudflare for routing, security, and performance delivery were impacted by the outage.
Some Big Businesses That Were Affected by the Outage
- X (formerly Twitter)
- Spotify
- ChatGPT
- Perplexity
- Amazon Web Services
- Canva
- Letterboxd
- Sage
- PayPal
- League of Legends
- Archive of our Own
- Genshin Impact
- Honkai: Star Rail
- Claude AI
- AT&T
- TMobile
- Discord
- Verizon
- Garmin
What is the Cause of the Outage?
Cloudflare CTO Dane Knecht later clarified that the outage was triggered by “a latent bug in a core service that powers our bot-mitigation system, which began crashing following a routine configuration update.
He wrote, “I won’t mince words: earlier today, we failed our customers and the broader Internet when a problem in the Cloudflare network impacted large amounts of traffic that rely on us. The sites, businesses, and organizations that rely on Cloudflare depend on our availability, and I apologize for the impact we have caused. Transparency about what happened matters, and we plan to share a breakdown with more details in a few hours.
In short, a latent bug in a service underpinning our bot mitigation capability began crashing after a routine configuration change we made. That cascaded into a broad degradation of our network and other services. This was not an attack. That issue, its impact, and the time to resolution are unacceptable. Work is already underway to make sure it does not happen again, but I know it caused real pain today. The trust our customers place in us is what we value the most, and we are going to do what it takes to earn that back.”
I won’t mince words: earlier today we failed our customers and the broader Internet when a problem in @Cloudflare network impacted large amounts of traffic that rely on us. The sites, businesses, and organizations that rely on Cloudflare depend on us being available and I…
— Dane Knecht 🦭 (@dok2001) November 18, 2025
Cloudflare’s Official Response
Cloudflare shared the official blog post stating that, “it was not directly or indirectly caused by a cyber-attack or malicious activity of any kind. Instead, it was triggered by a change to one of our database permissions, which caused the database to output multiple entries into a ” feature file” used by our Bot Management system.
After we initially wrongly suspected the symptoms we were seeing were caused by a hyper-scale DDoS attack, we correctly identified the core issue and were able to stop the propagation of the larger-than-expected feature file and replace it with an earlier version of the file. Core traffic was largely flowing as normal by 14:30. We worked over the next few hours to mitigate increased load on various parts of our network as traffic rushed back online. As of 17:06, all systems at Cloudflare were functioning as normal.
The blog also outlined the chart of the outage that highlights the volume of 5xx error HTTP status codes served by Cloudflare. Usually, this should be very low, and it was right up until the start of the outage.
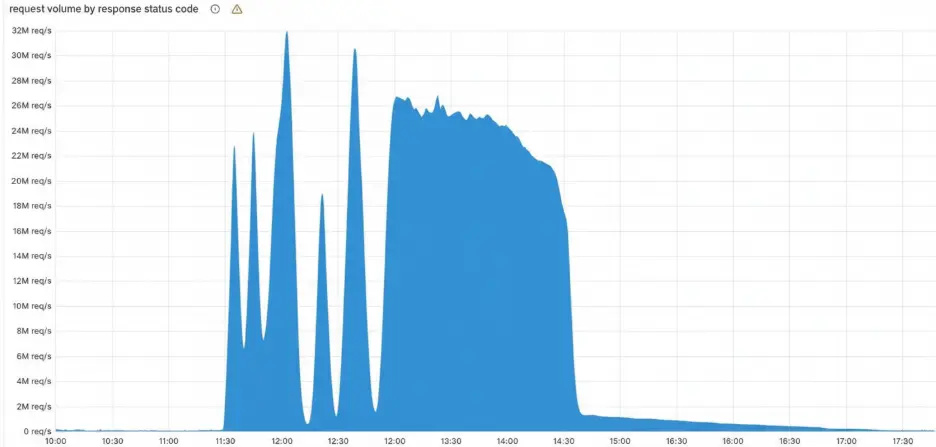
Cloudflare Outage Incident Timeline (UTC)
| Time (UTC) | Status | Description |
| 11:05 | Normal | A database access control update was successfully deployed, with systems functioning normally. |
| 11:28 | Impact begins | The deployment reached customer-facing systems, leading to the first signs of HTTP errors in client traffic. |
| 11:32–13:05 | Investigation in progress | Teams began analyzing unusual traffic spikes and rising workers’ KV errors. The initial assumption was that degraded workers’ KV performance was causing cascading issues across Cloudflare services. Various mitigation steps, including traffic rerouting and limiting account activity, were attempted. Automated alerts were triggered at 11:31, manual checks started at 11:32, and an official incident call was initiated at 11:35. |
| 13:05 | Impact reduced | Internal bypasses were applied to workers’ KV and Cloudflare Access, redirecting them to an earlier version of the core proxy, which helped lessen the overall disruption. |
| 13:37 | Rollback efforts begin | Engineering teams focused on restoring a previous version of the Bot Management configuration file after confirming it was the cause of the incident. |
| 14:24 | Faulty configuration halted | Automatic generation and distribution of new Bot Management configuration files were stopped once they were identified as the source of widespread 500 errors. |
| 14:24 | Recovery validated | Testing showed that reverting to the older configuration file restored normal behavior, and teams quickly pushed the fix globally. |
| 14:30 | Major recovery | A corrected Bot Management configuration file was deployed worldwide, stabilizing services and significantly reducing errors. |
| 17:06 | Full recovery | All dependent services were restarted, and the entire platform returned to normal functioning, officially closing the incident. |
Global Impact: How did the Market React to Cloudflare’s Outage?
Shares of Cloudflare dropped by nearly 3% in morning trading (New York Stock Exchange) after the outage, as investors grew cautious about the company’s operational stability. With Cloudflare powering more than 20% of global web traffic, even a short disruption becomes highly visible and carries significant ripple effects across the internet. Incidents like this underscore the vulnerabilities of centralized web infrastructure and reveal just how heavily businesses and users rely on a small number of major service providers.
(Source: TheEconomicTimes )
Why did Cloudflare’s outage affect so many services?
Cloudflare plays a critical role in today’s internet ecosystem, powering more than 20% of all websites globally. Its vast network supports a wide range of platforms, including social media, streaming services, gaming apps, and countless business tools. So, when Cloudflare experiences a significant disruption, the impact is immediate and widespread.
The recent outage highlights how heavily the online world depends on centralized infrastructure. With so many services built on top of a few major providers, a single technical failure can cascade across multiple platforms at once. This dependency leaves organizations vulnerable, as many rely on Cloudflare’s network for uptime, performance, and security.
What is the Current Status?
Cloudflare has confirmed that the outage is fully resolved and that all services are now operating normally. The issues that caused widespread disruptions across multiple platforms have been addressed, and the company has restored stable performance across its global network. Cloudflare’s status page reports that all systems are operational, with no ongoing spikes in 5xx errors or latency.
Final Notes
In conclusion, Cloudflare’s outage comes just a month after a significant AWS disruption, underscoring how dependent the digital ecosystem has become on a handful of core infrastructure providers. While Cloudflare responded quickly and restored normal operations, the incident highlighted the importance of robust failover systems, continuous monitoring, and thorough testing of configuration changes. As platforms increasingly rely on third-party infrastructure providers, maintaining resilience and preparedness for such disruptions remains crucial for ensuring uninterrupted user experiences.
manvinder Singh
https://www.hostingseekers.com
Manvinder Singh is the Founder and CEO of HostingSeekers, an award-winning go-to-directory for all things hosting. Our team conducts extensive research to filter the top solution providers, enabling visitors to effortlessly pick the one that perfectly suits their needs. We are one of the fastest growing web directories, with 500+ global companies currently listed on our platform.